
Kicking the tires on dbt Metrics
Daily Active YAML is up and to the right
The dbt metrics layer has arrived.
Sure, it’s early. Yeah, it’s “only half of the overall project”. (dbt Server being the second half.) But this ambitious Github issue has now graduated, met its better half, and is expecting new life sometime in the next 40 weeks.
So how’s it feel?
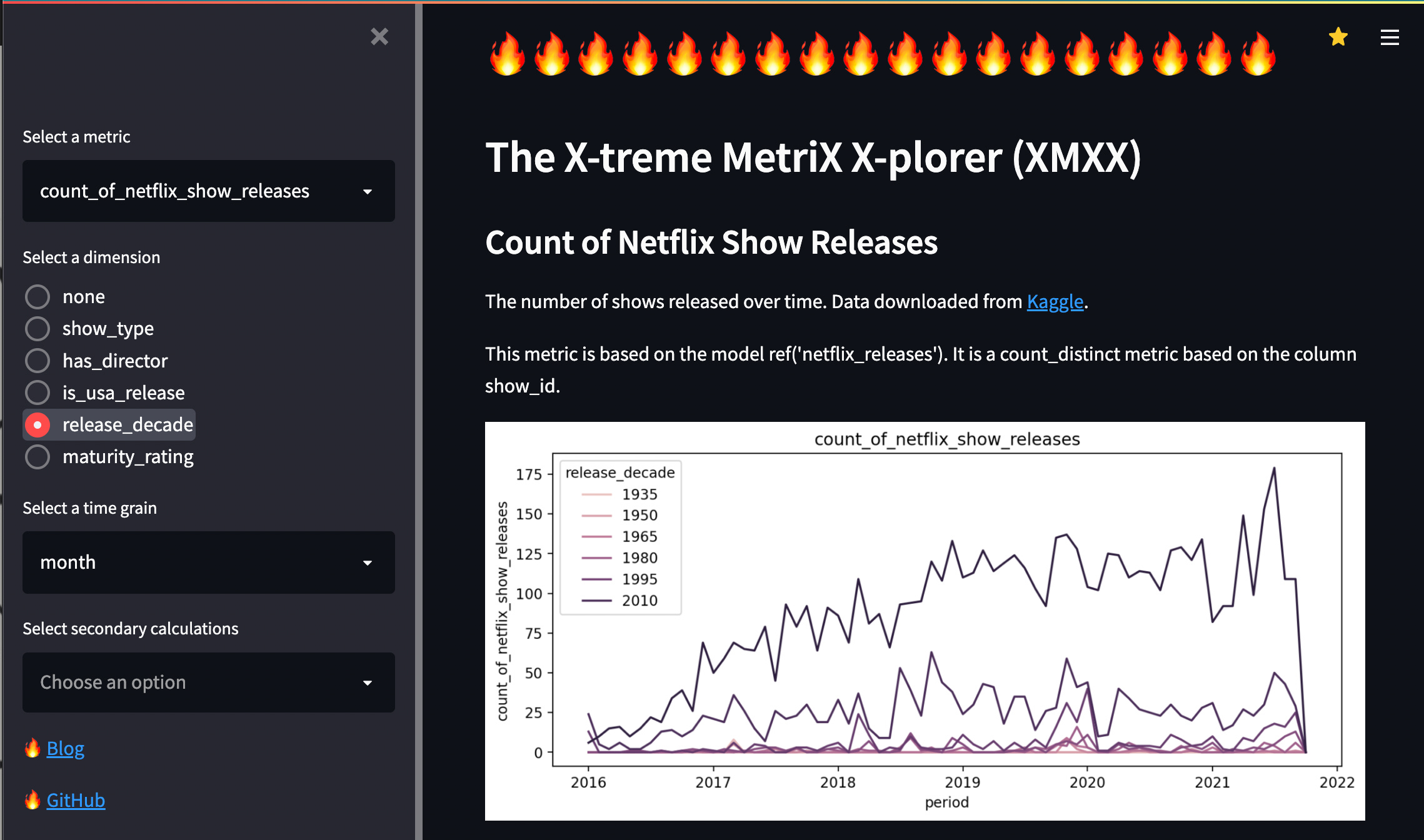
To find out, I stitched a head onto the headless BI layer that’s generated so much buzz this past year. The result may not be the next big thing in data, but it demonstrates the value and opportunity this new layer presents to the ecosystem and what utility it might have for data practitioners today.
I present to you, the Xtreme MetriX X-plorer (XMXX), a fully functional Streamlit app that hits a personal “data warehouse” in my AWS account.
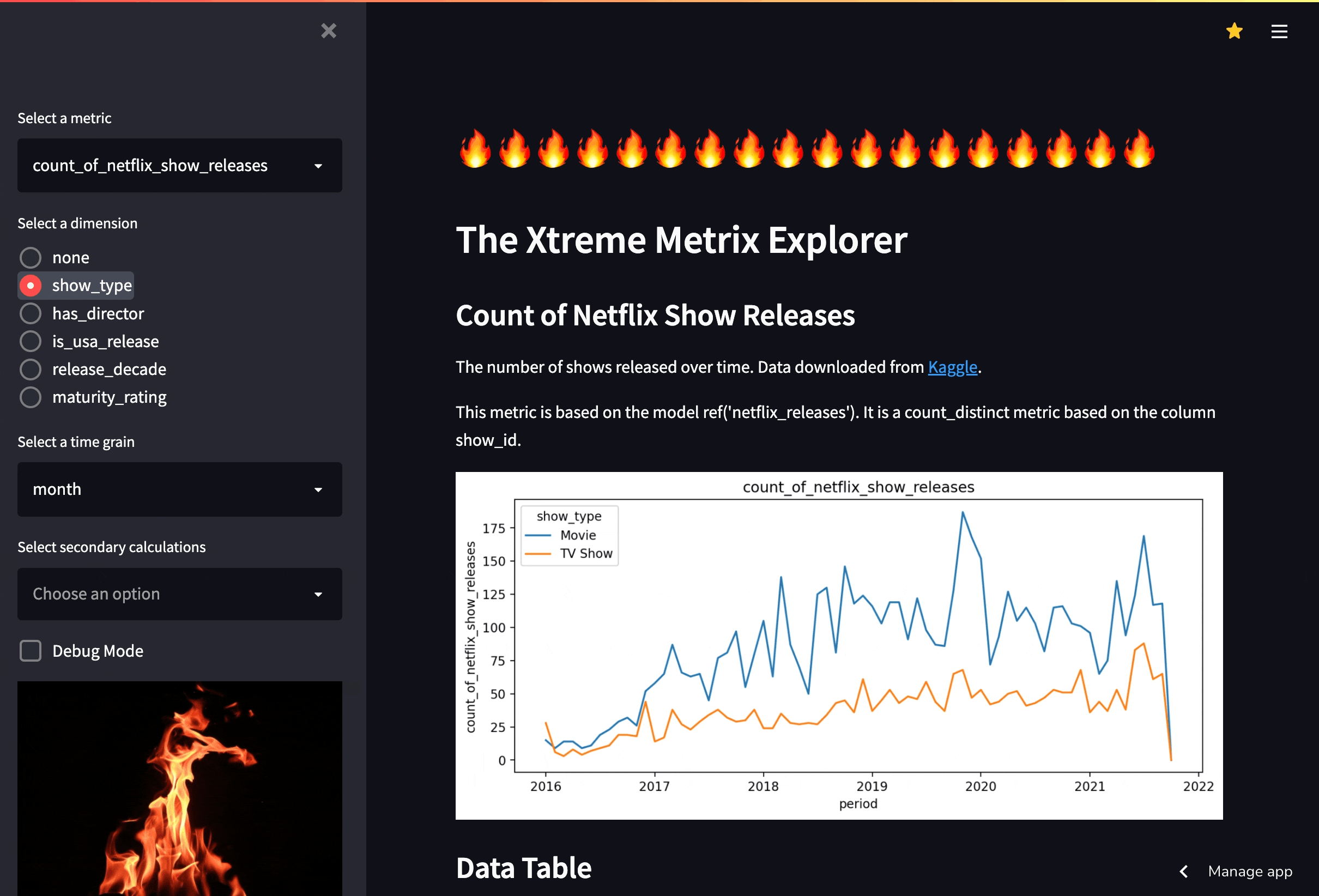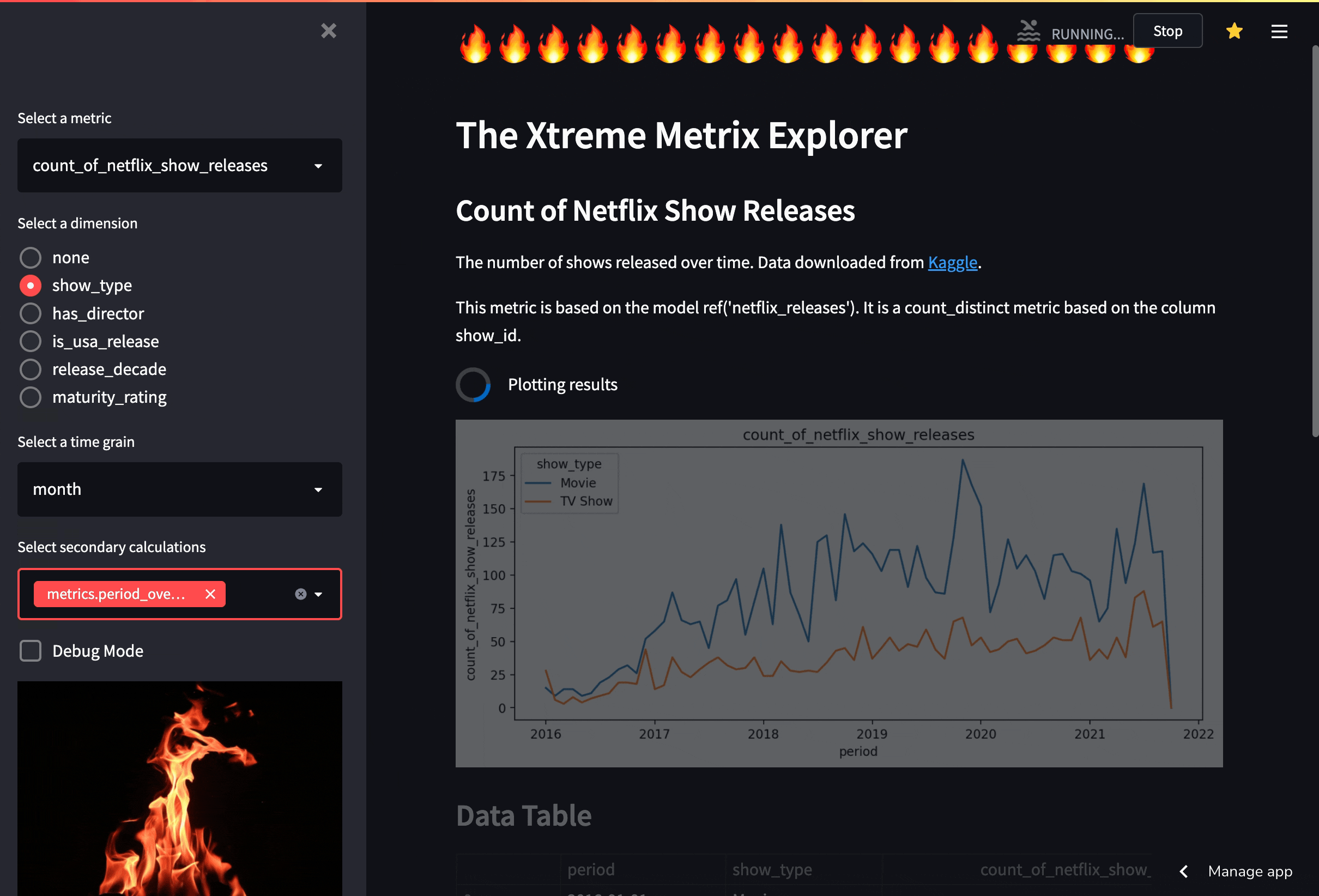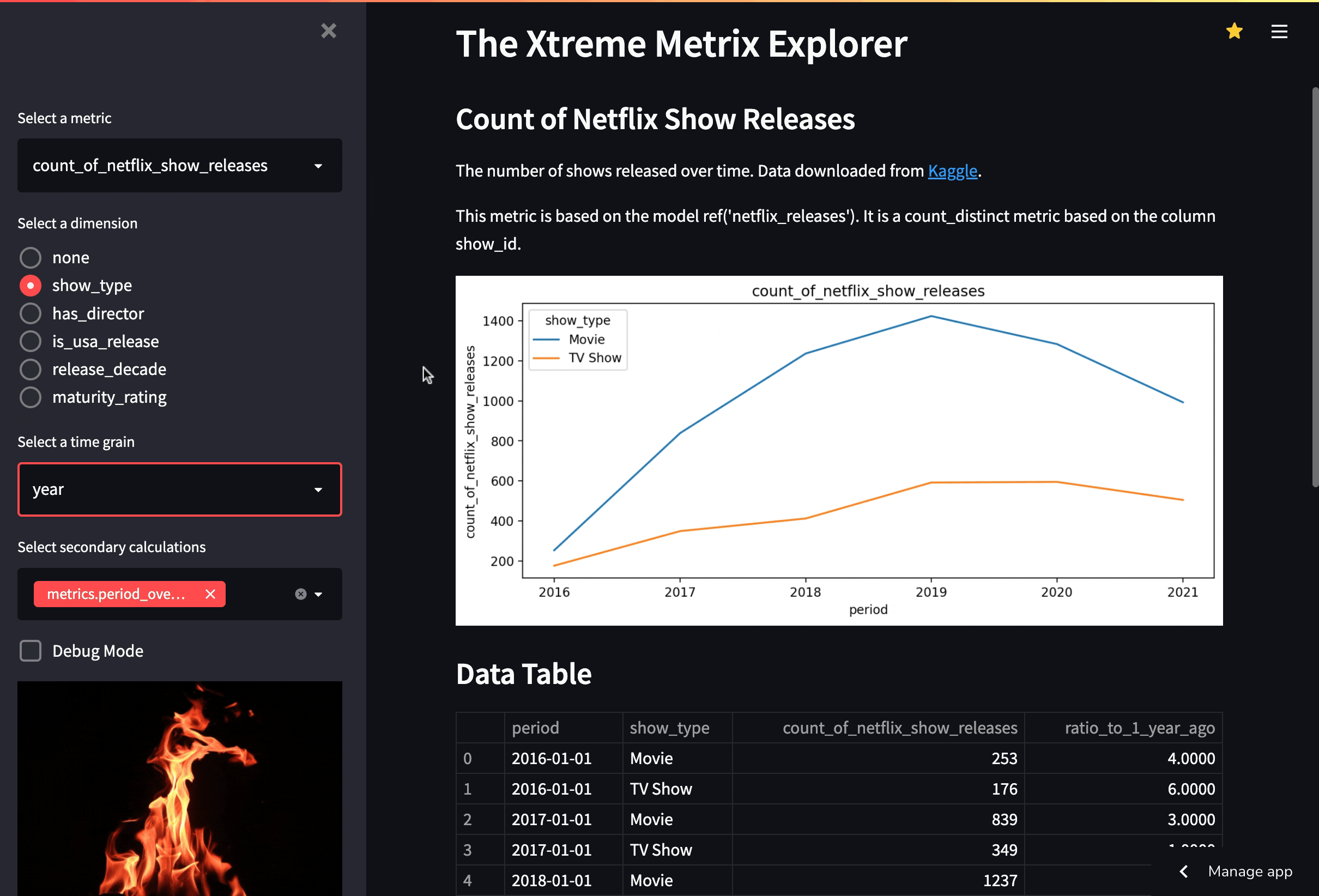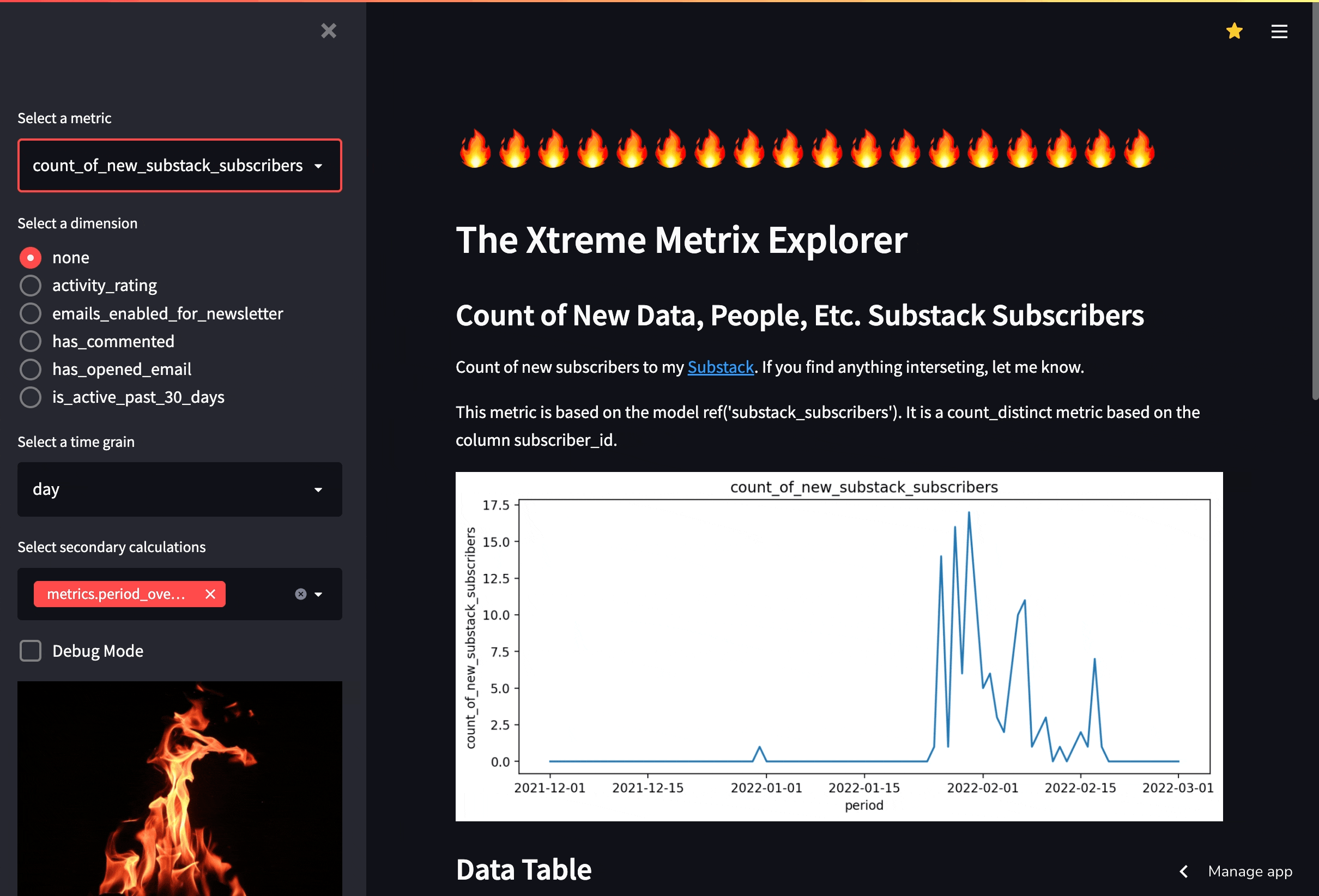
XMXX demonstrates the core value of the available half of the metrics layer: it consolidates all business logic on the database side, rather than the tool side. Below is a breakdown of the effort it took me to build this app:
10% finding data
20% Streamlit app hacking
15% setting up the dbt project
5% fire
50% networking
Building XMXX required next to no time spent creating table parsing logic, inferring possible aggregates for each field, writing SQL code to generate the hundreds of potential combinations of dimensions, time grains, and secondary calculations that the tool is capable of. Instead, I just had to list the dimensions of the metric from the dbt manifest, compile a query using the dbt compiler, and hit the database holding the data.
In other words, the metrics layer serves as an open-source backend to your data-driven tool.
That means two things for me and the XMXX team in Columbus:
{kind=link}
We can handle any metric thrown at us without writing any new code.
We can focus all our energy on developing a great interface with more fire.
Tools like Lightdash already piggyback on top of dbt’s data graph in a similar way, but they also have to bolt on their own interfaces to dbt’s data model, often using the “meta” fields. Metrics nodes and metrics Jinja functions, as first-class citizens in the dbt graph, feel more natural within the dbt developer experience. When adding new metrics, it didn’t feel like I was adding them for XMXX (although I was). It felt more like I was enriching the dbt project, and XMXX simply got to reap the rewards.
My hunch is that, for tool developers, the dbt metrics layer is going to be a huge boon. Not only can they offload many of the technical challenges to dbt’s logical layer, but they have much less work to do incentivizing users to try out their tool. They free themselves up to focus on the experience.
Should analytics engineers clear their sprints to build out some metrics, then?
For me, the answer is not yet.
The metrics layer may best be understood as an open-source backend for BI tools. (Hence the name, headless BI.) These are still early days for the category, and there aren’t a lot of “heads” out there that practitioners can try on for size. Existing BI tools already have their own backend implemented, which teams have already plugged into and spent months or years tuning.
Further, the value these existing BI tools provide is found in other experiential features, not the fact-table-to-chartable-table conversion that the metrics layer powers. The SQL generation problem is more of a “complexity tax” on the tool developer that the metrics layer takes away.
There is one exception: if a team needs to materialize one ore more “cuts” of a metric by multiple dimensions in your warehouse. These could be generated as a way to snapshot your metrics, to export for business users, or to build feature tables for further analysis. In these cases, the metrics macro provides a convenient way of generating the sorts of date-splined tables needed. Although it does feel different, it’s not bad, and it’s better than many of the alternatives.

We actually have several use cases like this at Whatnot, and I plan to give it a shot in the coming weeks. The basic pattern is:
Build a single high-quality fact table with the necessary dimensions and time columns
Define the desired metrics in YAML
Materialize the metrics, including any secondary calculations, in a new model using the metrics macro
Optionally, join or union many of these materializations into a single model
It’s a useful, repeatable pattern, but probably not a killer app for most users. I’m waiting to see how vendors respond to the new functionality before I make a concerted effort to metricize our models. XMXX could easily be a plug-and-play Hex application, and Hightouch could easily leverage the metrics functionality for their audience builder, for example.
So, how does the metrics layer feel?
It feels new. A second-date-newness, with a healthy balance of awkwardness, familiarity, and novelty. Like its older sister exposures, dbt Labs is innovating in public with the metrics layer, rather than providing an elegant simplification of required data management operations.
The experience of generating a metrics table feels like less of a select and more of a summoning. The spellbook reads, “Open a text file and type '‘metrics'“ three times fast: {{ metrics.metric(metric_name=”foo”) }}. Your metrics table will appear.“ It is SQL. It is a macro. But the package pulls logic from somewhere new, somewhere that is not the database, from the metrics heavens. dbt consults the Forms and returns with answers.
I have concerns: there’s a lot of YAML, there’s not a lot of aggregates, “drill-downs” may pose a challenge, there’s new technical jargon to grok — grains, dimensions, metrics, secondary calculations. As a Looker veteran, I’m used to the abstractions, but they take time for new folks to get used to.
However, if first impressions are any indication, dbt Labs is doing something special with the metrics layer. They have now set up intuitive interfaces for analytics engineers to own. “To shepherd data from raw source to key metric,” is as apt a description of analytics engineering as any, and it can now be managed coherently in a single workflow.
But ultimately, it’s the ecosystem that stands to benefit most. If a bad data engineer can hack together a “BI tool” in a weekend, there’s no telling what the real professionals are going to put out there in the coming months.
Great little blog post, maybe even motivating me to write some of my own soon. Hopping over and trawling through your blogs from the Dagster slack channel.
I've introduced my company to Dagster, DBT and Superset, but I'm a little sad that there isn't more integration between DBT and Superset (DBT was the last tool I added in after hearing so many people rave about it).
That said the Superset API is pretty excellent so there's still time for better integrations. Really the analytics piece of the slice just needs to be incredibly light.
Great little blog post, maybe even motivating me to write some of my own soon. Hopping over and trawling through your blogs from the Dagster slack channel.
I've introduced my company to Dagster, DBT and Superset, but I'm a little sad that there isn't more integration between DBT and Superset (DBT was the last tool I added in after hearing so many people rave about it).
That said the Superset API is pretty excellent so there's still time for better integrations. Really the analytics piece of the slice just needs to be incredibly light.