

This is essay #6 in the Symposium on Is the Orchestrator Dead or Alive? You can read more essays from Ben on Medium.

How much time have you spent managing tasks on an orchestrator? Hundreds of hours? Thousands? Whichever it was, those were some low-value activities, and you probably felt that way too.
The root problem is that the orchestrator tries to control the data operations, rather than letting the operations stem from the data.
Why do we have orchestrators?
tl;dr: legacy.
As Louise wrote, the data orchestrator is “a software solution or platform responsible for automating and managing the flow of data across different systems, applications, and storage locations.” I would supplement it with the idea that, in the end, an orchestrator is a stateful solution to manage the execution of scripts.
Looking back, the need for data orchestration stemmed from the complexity of triggering logic, where simple script scheduling failed to account for dependencies. One script depended on another, and there needed to be a stateful software piece in the middle to not only trigger the entire process but to ensure individual steps were started only after all their upstream dependencies had successfully completed.
As a standalone brick, the orchestrator serves multiple purposes, the main ones being:
Keep state: keeping tabs on what has happened and what hasn’t is likely the core feature of the orchestrator.
Trigger stuff: the actual mechanism of executing the script, often using a set of parameters set at the task or job level.
Enforce dependency constraints (DAG): sort out which script should be executed before which and make sure there is no loop.
Surface logs: provide a comprehensive view of task statuses that serves as a troubleshooting entry point.
What’s the issue?
Hint: it’s the orchestration.
I could ramble on about the maintenance time spent managing deep dependency graphs (high number of successive tasks), the latency they introduce by forcing workflows to adjust to the slowest task, the cost they bear in an already resource-hungry practice, their poor interoperability with modern tools (or utter incompatibility like with stream processing), the burden they put on data consumers who are forced to depend on engineering work for the tiniest updates…
But, in the interest of keeping it efficient, the orchestrator’s problem boils down to two things: they’re just another brick in the stack, and, most importantly, new data technologies don’t need them.
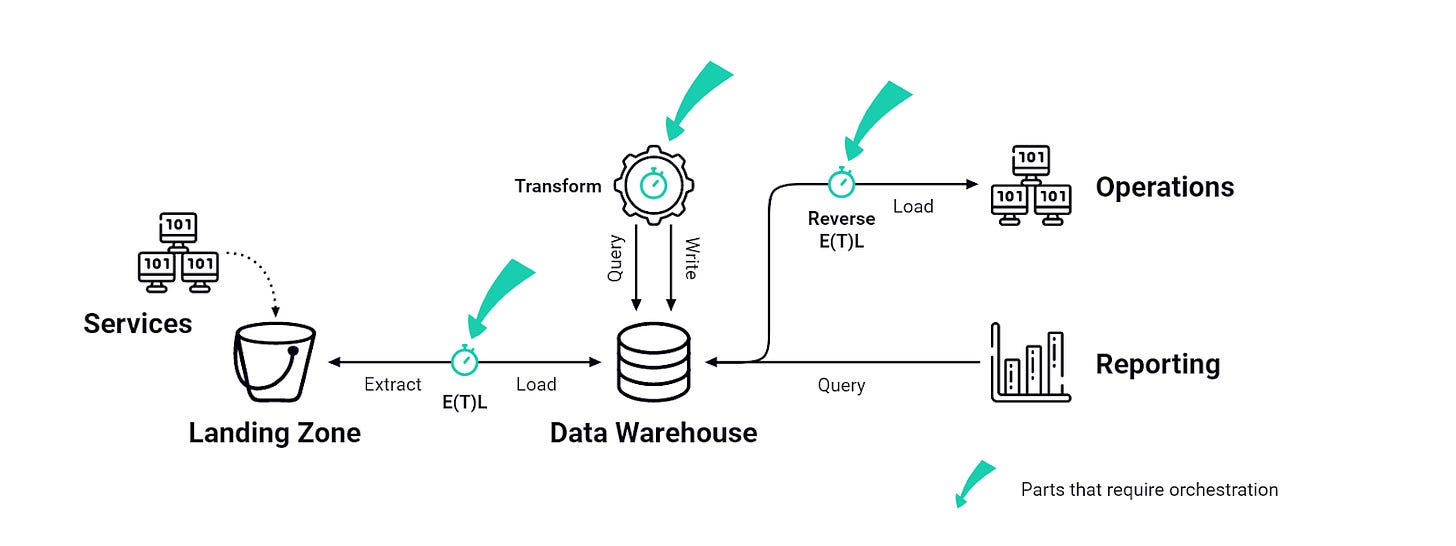
What are the post-orchestrator people doing?
Just-in-time data ops.
Displacing the orchestrator means removing synchronization overhead, and the chief way to do this is to try and make the time of execution matter less. Today, this means implementing either Asynchronous Processing or High-Frequency batches.
High-frequency batches
Let’s cover high-frequency batches first because I see it as an aberration.
High-frequency batching is the idea of running processing steps at very high frequency (per batching standards) – for instance, every 5 min or so. In doing so, one can almost treat every independent task as asynchronous. This helps make individual tasks run independently, without the need for a stateful orchestrator at the helm, but it forces you down the darker path of one of the hardest trade-offs: agility for cost.
Anyone who has tried running high-frequency batches at scale has seen two challenges. First, latency adds up fast - it doesn’t take a deep dependency graph before high-frequency tasks stop correlating with high-availability datasets. And second, pricing hurts. Most data solutions aren’t designed for this usage for a simple reason: running a LEFT JOIN every 5 min means redundantly scanning a ton of data.
Asynchronous processing
Asynchronous processing, or continuous systems – think incremental engines like Stream Processors, Real-Time Databases, and to a certain extent HTAP Databases – do not require an orchestrator since they are continuous in nature and data is self-updating: a change is instantly reflected in consumer systems and downstream views/tables.
For anyone who isn’t too familiar with streaming yet, that’s the difference between Pull and Push data operations: the former requires you to constantly trigger the actions you would like performed (like in the ETL / ELT model for instance) while the latter computes and propagates data points passively and incrementally. No orchestration! Each task is almost like a microservice, a data service of sorts.
Unfortunately, Benoit already beat me to quoting the “Why not Airflow” documentation, so I’ll spare you that much. But as mentioned earlier, one of the core difficulties of orchestrators is interoperability: you simply can’t orchestrate everything. It introduces complexity and latency into your data operations and is generally a very efficient way to obliterate many weekly hours into an activity that ultimately shouldn’t exist.
Imagine if everything you run in prod had to be orchestrated, that would be the death of agile. Really, why is this still a thing in the data world? (Rhetorical question, please refer to the first paragraphs).
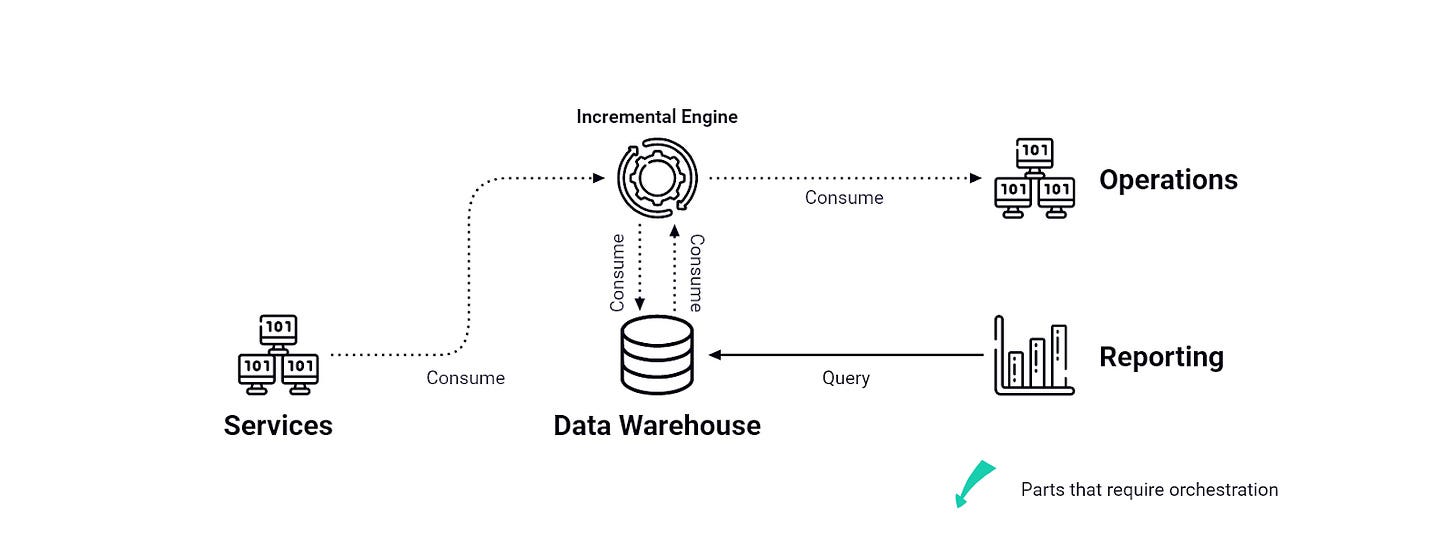
What’s the new toolbox then?
It’s already here, sort of.
If you’re spending time fixing an Airflow DAG, sorry for saying this but that’s unlikely to be your greatest contribution to your company. Fortunately, the alternatives are out there, so it’s already down to your organization’s techno-political leadership to make that choice. With regards to spinning up data services, all the asynchronous processing options mentioned earlier are already live and running at scale in an enterprise near you.
What’s really missing is some form of reusable Control Plane with basic enforcements: ensure that the Acyclic and Directed aspects of dependency rules are met, and surface operational commands and statuses at a central level for convenience. This is more of a generic DataOps tool that inherits some of the Orchestrator responsibilities, especially on metadata and command exploitation, albeit without meddling in the task lifecycle – hence no longer a mandatory piece of the stack. That’s where the “active metadata” trend could be an interesting play by acting as a passive observer of the pieces involved, rather than intruding on the data operations by having an active role.
At Popsink we have no extra brick for orchestration, and it saves us time and money. We did end up building our own control plane for convenience, partly because some of the open standards today are incompatible with the idea of not having an orchestrator (like OpenLineage which is built on the foundation that tasks have a “start” and an “end”).
Yet it works great: jobs are now asynchronous constructs with passive consumers that do not need to pull the data when predefined conditions are met. To use a metaphor I like: we’re working with pipes instead of buckets. There’s a lot less lifting so you can sit back and watch the data flow.
Final words
You made it!
In many organizations, data products are still the output of a long line of data manufacturing that requires a plethora of orchestration. But it doesn’t have to be this way, the solutions are already out there, like the Streaming Workflow Builders Hubert mentioned or what we’re up to at Popsink.
With the ongoing shift to continuous operations, it’s worth exploring what the post-orchestrator world feels like, if not for your sanity then for your wallet. I also grew pretty fond of the term “data services” as it sits well with the idea of on-demand data subscription as opposed to off-the-shelf “data products”.
It’s going to take a bit more time to reach full feature parity and for good reusable standards to materialize, especially as current active metadata and lineage systems are deeply rooted in orchestrators, but the capacities are already here.
It’s time to move on with your life.
 | A guest post by
|
I like this analogy in the article:
“we’re working with pipes instead of buckets. There’s a lot less lifting so you can sit back and watch the data flow”