

Two Party System
Every action has its equal opposite reaction
This is Part 2 of 4 in a series, Knowledge Isn’t Power.
In my small and mostly professional feed of data voices and news, Lauren Balik stands out for having hot takes that actually pack heat. No other writer I’ve encountered is so ready to burn down the modern data stack, and everyone standing around it.
You’re probably on fire already, if you’re one of her usual targets: clueless heads of data, rent-seeking analytics engineers, smug venture capitalists, nouveau riche data celebs. Lauren has positioned herself opposite the MDS establishment in every way — she writes on Medium not Substack, she sells services not products, she brands herself as “Getting Stuff Done” not “Building Big Stacks”.
But, in pushing back on the Modern Data Stack, she does the community a service: she forces practitioners to question how closely “modern data team” and “modern data stack” need to coincide.
Here, I want to examine a particular claim which we can call the Middleware Hypothesis. It goes like this: Modern data teams that settle into the no-man’s-land between traditional business domains and high-functioning centralized teams will produce data products of little value, gobble up resources better allocated to other teams, and fail to grow into a successful independent arm of the company.
In her words:
Ultimately, [data teams are] all just the shuffling around of workflows and money, within individual companies and broadly across the market in aggregate. Reports that could be done in an application are now passed through Snowflake, then put in a BI tool, incurring costs the whole way through… and the middleware Clueless layer is allowed to bloat in terms of complexity, products, the ‘T’ of transformation, and human beings, which eventually devolves into serving as a bloated buffer between Data Producers and Data Consumers. — The Modern Data Stack Through The Gervais Principle
Look, I don’t like being called a clueless piece of human middleware, but honestly — it’s an apt description of my own stint as a head of data. Fortunately for me, I am a parent, so I was already accustomed to that sort of work.
I’m going to argue below that the Middleware Hypothesis is caused by a lack of vision — that middleware data teams do not successfully reconcile, at the organizational level, two competing views of data ownership. These two views are:
Data is a public good meant to foster collaboration and society-building
Data is a private good meant to deliver specific business value
These are not technical beliefs, they are political ones. They are also not modern, although the way they can now be operationalized is. Executives, managers, DBAs, and operations folks have all fought about these issues for years. So let’s start there: who do we talk about when we talk about data people?
Of the people
There’s an oft-cited statistic that 3-10% of people in an organization are data people. But this statistic is usually stilted towards dedicated “data professionals” — those who operate within a dedicated database or generic business intelligence tool.
The numbers would look quite different if we considered anyone who reads a Google Sheet a “data consumer”, who updates a Salesforce object a “data producer”, who changes a Zendesk ticket schema an “analytics engineer”, or who migrates a product database a “data engineer”.
In fact, you could reasonably flip it around and argue that 90 - 97 percent of employees are actively contributing to the data economy. Certainly everyone that receives a paycheck is reliant on the payroll team properly managing its data.
I have a lot of respect for the folks who manage Google Sheets and SaaS applications but never got the “we’re actually software engineers now” memo. I’ve been the sole admin for Salesforce before, and know just how exciting “applied data engineering” can be when operating under an opinionated application data model.
A major difference between these front-line data doers and what I’d typically call “data professionals” is that the former have real, defined jobs in service of real, defined domains. These jobs are often deeply connected to specific systems - Netsuite, JIRA, Salesforce, Zendesk, Google Analytics. Data professionals, on the other hand, are trained to deal with data in the abstract, and focus on secondary uses of the data.

In most cases, these two groups get along fine. But when it comes time to divide job responsibilities — say, agreeing to data contracts, doing data cleanup for some other organization, ceding ownership of reporting capabilities — domain-embedded folks are likely to push back against the yokes imposed by centralized teams. Under enough stress, you might even see coordination against centralized efforts — a coordination we can call the Performican party.
Laissez-Faire Datanomics
The Performican party platform has three pillars:
Anyone is capable of creating reliable data insights and products, with access to the right tools
Business domains are responsible for defining their own views of the business and its metrics
Less centralized coordination will allow teams to more efficiently build the most valuable data products, in terms of both speed and cost
If that sounds a lot like capitalism, well, I think it’s a lot like capitalism. It puts the onus on business leaders to make investments that will actually speed up their business and allow them to make their case for being successful — or face the consequences.
If a CEO offers 2 million dollars to the company to invest in “data operations and analytics”, the rational Performican response is to ask for their cut of the pie, not support investment in a centralized data team that will build who knows what and squander the whole thing on needless Snowflake spend.

The bogeyman of centralized data organization is slow, detached from business value, and just not that useful to “the people”. There’s reason to believe it — a data team would have to stand up Dagster, Fivetran, dbt, and Looker to reproduce a cut of Salesforce opportunities that could be pulled in 30 seconds from Salesforce directly.
Return on investment is the operating mindset for Performicans. How much added value can a centralized team produce compared to domain-managed alternatives? With so many vertical solutions available, there is undoubtedly a way to solve any problem with full domain ownership.
Performicans simply say, “No, thanks,” to centralized data coordination. That causes some pain — perhaps only 80% of the possible questions can be answered by the chosen SaaS application. But it also inspires creativity and direct partnerships with other teams. Allocation of both attention and capital would go to only the highest priority projects, and fewer unnecessary projects would be built.
The Performican ideal is that of the empowered individual, situated within a domain. They are free to creatively apply solutions that serve a direct business purpose, without the onus of a centralized regime mandating the “right way” to do things. It’s a rosy view but not so unusual.
In practice, I think, many first data hires operate in this very environment. With absolute freedom, they implement a modern data stack, and their perspective shifts from that of a single domain, to something greater.
The Great Society
Across the aisle, the Platformocrats believe data belongs to the company, and ought to be redistributed justly, for present and future purposes. The data team is idealistic: they manage a platform dedicated to truth, they enable a fair competition of ideas, they cultivate a data democracy open to all who seek knowledge.
In practice, of course, these platforms consist of tables, and pipelines, and notebooks, and dashboards. Lots and lots and lots of them. But that’s okay, because all these objects are just by-products of making data available for more purposes, to more people.
A centralized team brings benefits: concentration of expertise, economies of scale, domain neutrality. Consequently the centralized team is going to advance a “big governance” ideology: centralized modeling, global conventions, best practices, certification processes. Any friction introduced at the individual user level is in the service of making the company as a whole move faster.
When the Platformocrat looks at domain systems, they see wasted talent and “garbage in”. Why import and manage a custom Salesforce package via a GUI when you could do a left join in a database? Those 20% of questions left unasked by Performicans? Aggregated across every domain, it adds up to hundreds of potential business questions. Leaving so much potential data value up to chance seems negligent on the part of the company.
Platformocrats tend to de-emphasize return on investment, and instead focus on making the pie bigger. By increasing the set of possible use cases of data — machine learning, advanced analytics, sellable data products — the platform can make the company as a whole better.
The invisible hand
Data teams, especially young ones, find themselves caught in the middle of these two competing visions: they manage a complicated data platform that serves only a couple key use cases. It becomes a centrally owned engine, but lacks domain fealty. Symptoms include the data team co-opting functions that should be owned by domains or withdrawing to build sophisticated data products with little adoption.
The chief reason this happens, in my opinion, is leadership. Data leaders — if “data” is going to be a persistent thing unto itself — must craft clearer visions, with clearer long-term value, that demand more of the company’s resources, attention, and respect.
But there’s a secondary reason in the Middleware Hypothesis, which is worth exploring: vendors.
In Balik’s political narrative, behind every conversation in the modern data ecosystem, is a seedy SaaS vendor pushing their point solution. And behind that vendor is the data platform: Snowflake or Microsoft or AWS or Google. And behind the platforms are the venture capitalists, eager to stoke the flames of data (i.e. compute) usage in every way possible.
Practitioners, then, face an endlessly juiced hype cycle around new ways to do their job. Whether it’s data mesh, semantic layers, reverse ETL, real-time analytics, data observability, data catalogs, or data mesh, data leaders are barraged with think pieces, all the while trying to figure out what their job actually entails.
They are like the blind men touching the elephant, but with vendors swapping out the elephant for other zoo animals every ten minutes.
This makes it hard to learn the craft, and even harder to explain the craft to stakeholders. The Modern Data Stack has been so successful in part because it provides a clear deliverable: at least we can deliver a dashboard with data to stakeholders and manage its lifecycle in a sane way. By explaining the stack, we can also explain our jobs.
Missing from this criticism of the Modern Data Stack, though, is criticism of the vertical data applications, like Salesforce, which also barrage domain users with point solutions. By abstracting the “real data work” of managing customer information into platform-specific language, we end up with communities of data people that don’t recognize each other at best, and which compete for resources at worst.

If it’s not Snowflake, it’s Salesforce. If it’s not Fivetran and dbt, it’s Tableau Prep, Tableau Studio, Tableau Connect, and Tableau Catalog. It’s hard to figure out where the data skills end and the application begins.
Don’t get me wrong — I think vendors can foster community and help teams move faster. I’ve got all the swag, I’m speaking at dbt’s conference, I’ve worked at a data stack vendor.
But vendors are not responsible for setting the vision for data usage at your organization, and in fact, they are actively engaged in making sure data spend lines up with their own financial interests. And if that means an expensive platform outlay, delivering little real value, that’s fine with their bottom line.
Mr. Data President
The blog post I’ve chewed on the most in the past year is The Missing Analytics Executive, in which an influential data executive at a successful data company searches for an organizational raison d’etre. Lack of representation at the executive level is, to me, the symptom that supports the Middleware Hypothesis most poignantly.
Balik’s analysis is standard Performican critique: company leaders need to ensure the return on investment for data initiatives is justifiable. But I think what’s happening underneath all of this is that organizations are trying to articulate what data leadership really looks like, and they’re willing to spend freely to find out.
This moment presents an opportunity for savvy data leaders who are willing to address the political tensions described above, rather than bury their heads in technological complexities.
I don’t have that playbook to share, but I do have two thoughts on improving the way Platformocrats and Performicans work together.
First, as Balik suggests, data leaders must better evaluate the return on investment of the data team and platform. There ought to be decision criteria for adding new resources, prioritizing projects, and proving value. We ought to know when Fivetran + dbt is not the answer. A platform is not just a set of tools, it is a vision for how the company should organize and distribute its knowledge of itself.
A potential decision point is whether a new platform component will provide value to two or more domains. If it will, the data is a public good and should be managed as such. If not, the data is better left to the original domain to distribute as needed.
Multiplicative value is more likely to occur when companies growing rapidly or operating with little coordination. In a steady growth situation, domains can probably meet demands by updating systems incrementally. In a high growth scenario, these one-to-one coordination costs become much more expensive, and having an independent platform has a much clearer pay off, despite a higher up-front investment.
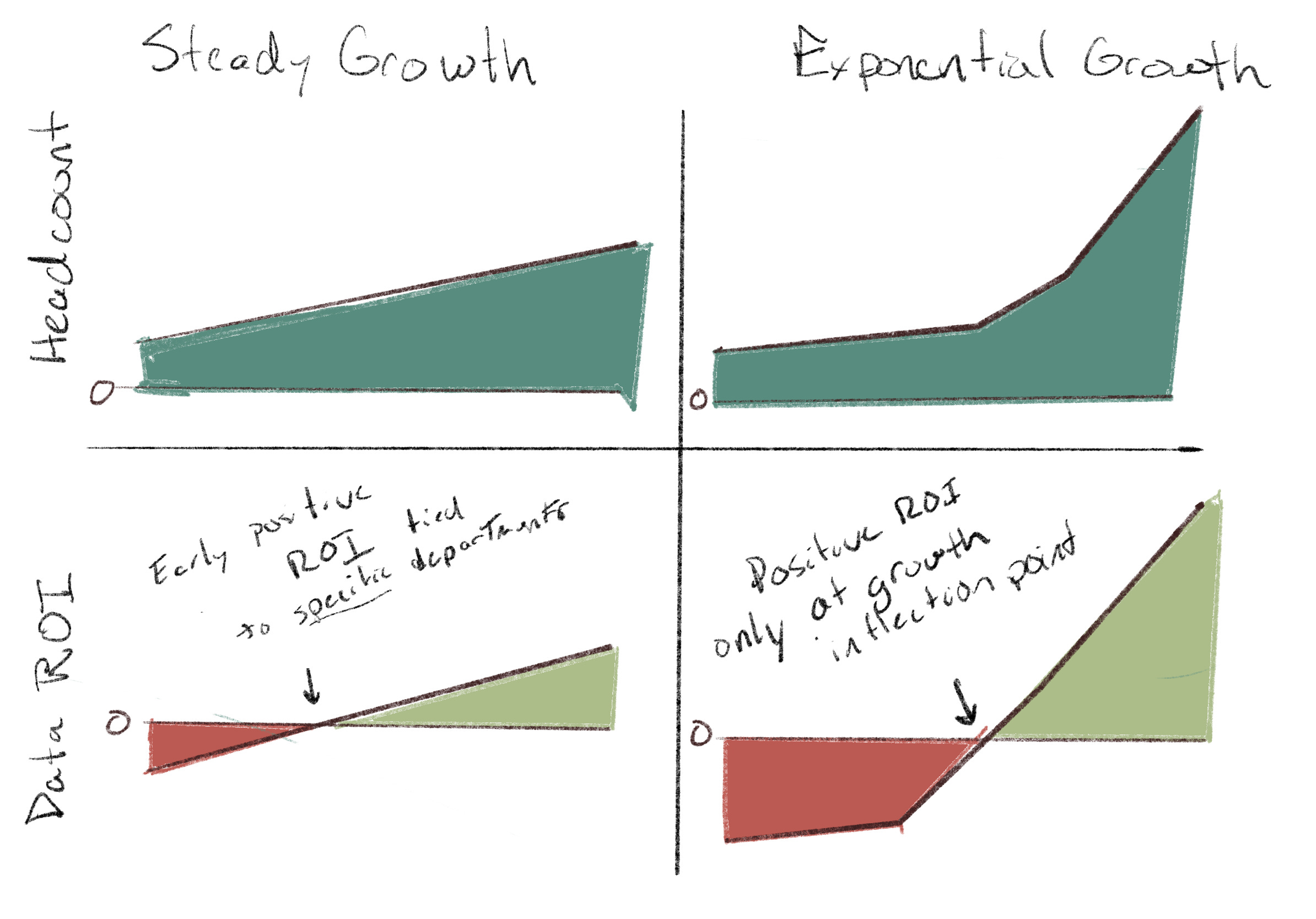
My second takeaway is that shadow wars between Platformocrats and Performicans need to be made explicit and resolved directly, because they are an existential threat to the platform investment. Articulating specific capabilities the platform enables and getting domain buy-in are critical political challenges.
Historically, this has meant “Domain users should use the BI tool, rather than in-application reporting”. But often, this is a low-value tradeoff, and potentially introduces unreasonable pain points — for example, multi-hour lag in data freshness. The reasoning for forcing users onto a platform tool should never be “We need to justify platform spend.”
A better path would be to find areas where the platform tooling can be made even more useful than the domain-owned tooling. Balik offers a potential way to do this — although I can’t find any of her LinkedIn posts referencing it right now — with the “Retool Data Stack”.
Retool is a low-code app-builder that makes it easy to operationalize basically anything. This capability to do things with data is something that dashboards lack, while also being customizable to any arbitrary use case a domain team might need. Building custom application management or integration tools could be a potential leverage point for data practitioners to transition from an analytics-focused organization to more valuable operational support tooling.
Whatever the approach, it’s important that data leaders recognize this moment as an opportunity — in the future, budgets will settle and patterns will emerge to box teams in. But for now, we have an opportunity to innovate, experiment, and lead to a new vision of data in organizations, so long as we articulate it first.
The problem with any two party system is that the third party is always right!! Chaosatarians for the win in data.
One of the funnier parts of all of this is that many of the Ayn Randian data products (Retool, Hex, etc) are made by ex-Palantirs selling into the social graph. It's too funny.