

This is essay #8 in the Symposium on Is the Orchestrator Dead or Alive?

Hell is other services.
If you’re building a system today, you live in hell, and you know it. Your eyes water at the scorched wasteland of internal applications. Your face burns as you stumble through a miasma of cloud infrastructure. Your skin sloughs off when you sift through some startup’s Swagger sewage.
There is no god in hell. I miss him, that emergent phenomenon of server racks, impenetrable protocols, and Cheeto-fingered priests. He used to dwell among us. We placed him in arks in office basements, in rooms 20 cubits high by 14 cubits deep. You could beseech God for assistance, and he would reply: “You are a sinner, full of error. Repent and resubmit.”
But he’s gone now, stuffed into data centers, and squeezed through tubes as we write letters through his stewards. Any chance at a personal relationship is gone, forever.
It’s a virus, this services thing. It dehumanizes everything and everyone it touches. Your face is an endpoint, your organs a module, your appendages a series of plugins to interface with supported integrations.
I have my own theories on how we got here: a secret AWS lab, a slipped hand, a cracked beaker, a drop of serum, an exposed toe. Regardless: everything is now unbundled, a hive mind of services backed by the same four companies, connected by cables to a room inside the earth’s molten core, where demons plug and unplug them intermittently to make humans dance between Twitter, Slack, and stale status pages.
We are survivors of a plague. This wasteland is our new home.
It’s changed us. If there’s one thing survivors don’t count on, it’s tomorrow. We need our infrastructure to rise and fall on demand, a virtual FEMA camp. We don’t get attached: yesterday’s architecture is today’s scrap heap, salvaged for only the most essential parts.
Survivors depend on the services they hate. They ambush them in alleys, plunge a needle into their intracranial space, and withdraw as much value as they can. Stitching services together into a soulless gesture at our cultural past is the only way to survive, in these end times.
The orchestrator, though, is a special kind of service.
Humans fashioned the orchestrator in their own image: it is an extension of the human mind, like another set of hands, like an infinite set of hands. The orchestrator, true to its name, is about turning the ideas of one into the actions of many. Orchestration is how psychological energy becomes kinetic energy.
The orchestrator’s essential role is this: run the thing. Run it now, run it later, run it after that, run it again if it fails, run it tomorrow, run it like this, run it over here, run it, run it now, run it again, again, again.
Yet as things have fragmented, the data orchestrator has found itself becoming not more important, but less. Like civilization itself, the data orchestrator was unbundled — the catalog-as-orchestrator, the warehouse-as-orchestrator, the sql-formatter-as-orchestrator. Instead of asking the survivors to run the things, the things are running themselves.
Data survivors, therefore, are even more adrift than others. One response has been to call for more control over the hellscape. Services are out of control. Data sprawl is unmanageable. We need better ways to coordinate. We need stoplights. Air traffic controllers. Bus schedules. Zoning ordinances. Crossing guards. Traffic lines. Segues.
These calls make sense — if you live in a civilization. But survivors do not sit on town councils. They do not go to the BMV and get driver’s licenses. They do not slow down for children at play.
Getting all these services, all this activity, to make sense, is a daydream of a time lost. It will not happen — not here, not today. But that doesn’t mean all hope is lost.
What if we built an orchestrator, not for architects, but for survivors?
Chaos. We would embrace chaos.
We would build tooling that is, above all, versatile and fast. It could be triggered from anywhere at any moment. It would have no opinions. It would require no thinking, no planning, no setup. It would be dangerous.
Hellscape tooling is dangerous. We have plenty of examples.
Adopting Segment is like handing out an assault rifle to every man, woman, and child in your cult. Without warning, you can go from having no user behavior events to having millions, billions of events flowing into Segment and thence into seven other systems. The startup cost is next to zero: you click some buttons, turn off the safety, and press the trigger whenever a user touches your product.
Using Segment will result in pain, agony, and analysts writhing on the floor, their legs shorn off. Segment does not protect you. Segment is not your friend.
But Segment works, because Segment is fast. Datadog, similarly, is fast, and it also penetrates your systems, nestling into their squishy insides to feed and grow. Datadog is valuable with just a couple metrics, but every additional sacrifice provides more new correlations, more value within the same interface.
Datadog will balloon into an unmanaged mess of millions of metrics. It doesn’t matter, though, not really — the first concern is to survive, and to survive, you need to hit your target. You don’t say, “I wish Datadog had fewer metrics,” you say, “I wish Ripley never learned Kubernetes.”
On the orchestration front itself, we have examples: GitHub Actions, for example, is not a control plane — the only useful part of its UI is a button that generates a status snippet you can embed in the README. It has no local development story. If you are creating a workflow from scratch, you will experience nothing but pain.
Github Actions thrives because it eschews any meta-narrative around what it should be used for, who should use it. It’s just Actions. It runs things. And with a marketplace of over 18,000 actions, chances are that you won’t even know how awful the developer experience is. It’s just ready for you, ready for action, ready to run code.
Here’s the through line for hellscape tooling: they cater to the individual, not the organization. They spread out across survivor clans and create long-distance dependencies between people who don’t know each other. And they are fast, requiring no thinking or training, just an initial thirty-second trial and error period to find the most ergonomic way to fire the thing.
The system emerges from activity; it’s a bottoms-up phenomenon. But this also means that the system’s survival is tied to its penetration into the culture. Its goal is not to evolve a single perfect organism, but to spawn an infectious alien growth that occasionally metastasizes into massive new fauna.
Simplicity and speed. This is where current data orchestrators fail. They make you think, not just about their opinionated frameworks — directedness, acyclicity, node/edge graph distinctions — but about whether they are even the right way to do a task.
Data ingestion — one process an orchestrator must own — illustrates this perfectly. Managed tools are easier for the simple case; managed resources such as Snowpipe are more effective in the advanced case.
The Snowpipe case is informative because it highlights the architectural limits of current orchestrators. A Snowpipe executes SQL whenever a new file lands in storage. It uses a message queue to trigger the compute, which updates the target table within seconds.
The Snowpipe doesn’t have good ergonomics. The monitoring sucks, it requires substantial infra work, and troubleshooting it is awful. But it is, above all, fast and simple. If a Snowpipe works for a use case, it’s probably the best solution — bypass the orchestrator.
There is a broader post-apocalyptic trend toward serverless pipelines. The DAG itself has been stuffed into a little box that’s run on ephemeral compute: event-driven, cross-platform, single-step executions, with fast code execution.
This leaves the orchestrator in a dissatisfying middle ground — neither dominant enough to bring every workflow to heel, nor flexible enough to spread virulently across teams. But what if the Snowpipe model was the core of the platform? What if, instead of DAGs, we littered the world with even more tiny services mediated by a message bus — pouring fuel on the fire, rather than trying to put it out?
It would be a push towards a distributed, business-level task manager. The chief adaptation would be to move to an entirely activity-driven model, and a consequence would be that the orchestrator would become flat. Not tall buildings that form permanent infrastructure, but a flotilla of boats drifting on a sea of activity. Nimble, mobile, discardable.
How many applications in the unbundled data stack could you power with a message bus, a Lambda function, a database, and access to a shared resource configuration?
All of them?
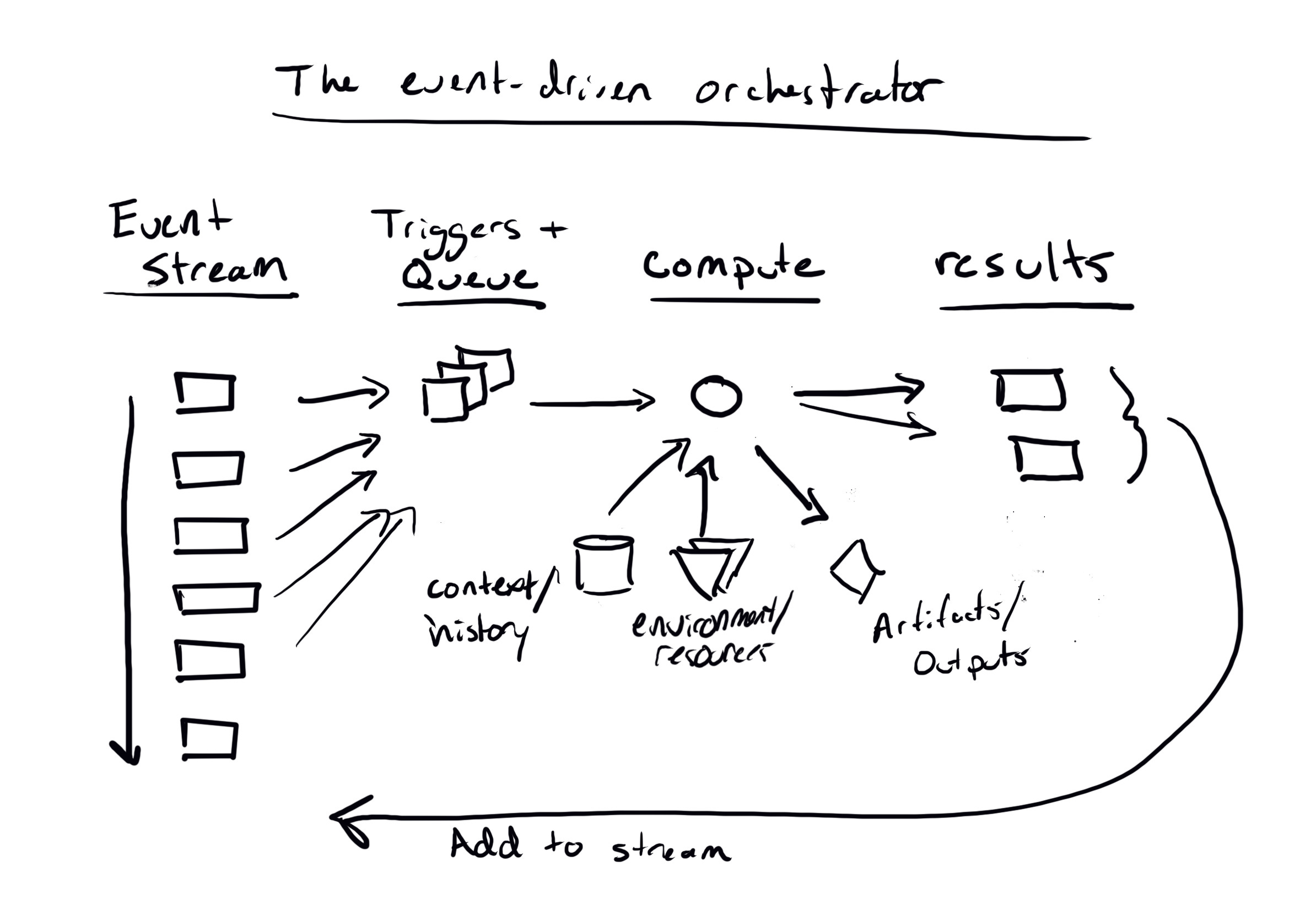
The orchestrator that’s useful is the one plugged into everything. That’s the interesting play from the data catalog — in a reactive environment, awareness is as important as skill. The orchestrator is losing today because it’s not fast enough to onboard the use cases the engineers want, and it’s not simple enough to justify displacing or running managed services through it. It needs to do both.
I’ve sketched out aspects of this chimeric product before — it’s part Segment, part Zapier, part Airflow, part Lambda function, and part Datadog. It doesn’t have to manage the compute itself — who cares whose EC2 instance it is — but it needs to have its tentacles in everything.
Here are the essential elements:
Event Bus: Ingest every potentially relevant triggering event. Every single object change in S3, every Snowflake user query, every test failure, every new hire, every first kiss, every lame icebreaker. It all goes in, or at least essential derivatives do. This is your potential energy, the reptile sensory brain, the primordial soup from which all resulting process emerges.
Environment: A bespoke orchestrator has over a cloud provider its ability to adapt to a particular context. The orchestrator speeds up development by making the environment easy to manipulate. It should take two minutes — literally two minutes — to write a task that queries Snowflake and sends a Slack message with a summary of the results every hour.
History & Context: The orchestrator embraces chaos, but only of a certain kind: ordered chaos, not wasteful chaos. If you tell it to fire at anything in its periphery, it will do that — then stop. This requires some meta-awareness, retries, task ids, and the like.
Artifact Catalog: Passing data between tasks is one of the key elements that drive DAGs. But artifacts are simply a subset of the environment. They are, essentially, an address and an object type. That’s not to say they’re simple — but as dbt has shown, if they are properly cataloged, passing them between operations is simply a matter of having the right context and name available.
Results and Monitoring: The orchestrator feeds itself, an Ourobouros of data processes. It’s directed, but it’s not deterministic, not necessarily. As each process completes, it adds results to the activity stream, which triggers downstream processes. But that’s not all: high-level systemic monitoring must be a primary concern to support all the chaos that’s being generated.
In the event-driven world, the graph exists, but it emerges from the architecture, rather than being the primary concern. You don’t control it, you create it, much in the same way you don’t truly control the activity patterns of users or the correlations of metrics in your infrastructure. You build funnels and piece together the processes after the fact.
And that’s the wedge the orchestrator can latch onto: the more chaotic the landscape, the more useful intelligence is. Compute is the content; the orchestrator is the feed.
Chaos or control?
It boils down to activity or graphs.
A desire to control and unify leads you to dbt: a comprehensive description of the ideal state, an approximation of the übergraph. This is a convergence problem. You have an idea of the world, and the challenge is to make it a reality.
There’s a place for this in our world, even today: graphs are thunderdomes, the last remnant of real human culture, a sealed-off sphere where contests can be fought and arguments can be settled.
But thunderdomes are tiny, and the wasteland is enormous. There are so many teams out there who want to run so many things. Many of these are terrible ideas that might result in catastrophe.
The orchestrator should make catastrophe easy.
Our descent into services hell is the perfect opportunity for the orchestrator to become the authority on the environment, to connect — and disconnect — services, to arm survivors with the intelligence they need to react to new threats and to monitor the sliver of reality they care about.
The orchestrator does not have to settle arguments or broker consensus. It doesn’t have to choose between truth and lies, monoliths or meshes, good or bad quality— why not do all of it? Its natural role is as an arms dealer, distributing compute, secrets, data.
Existing tools are moving towards a less controlled model, but not fast enough. Astronomer’s push-button deployments, Dagster’s declarative scheduling, Prefect’s UI-driven flow registry, Datahub’s stream-based metadata ingestion, Atlan’s Zapier-like metadata actions.
How much of this boils down to an event stream, trigger logic, and a Lambda function? Make it lighter! Make it faster! Make it simpler!
But don’t make it weak, leaving engineers in the cold. Give survivors the tools they need to do ludicrous things. They don’t want to wait at bus stops, they want to jerry-rig ATVs and sky-hook onto passing choppers and wave chainsaws at zombies.
Man’s descent into chaos positions the orchestrator to become one of the few services we trust, a bulwark against the neverending hordes of point solutions. The orchestrator should applaud every new category, every new cloud provider, every bit of fragmentation, because each one adds the cacophony that can only be managed by a service that welcomes it.
There is no longer any direction, any acyclicity, any distinction between nodes and edges. Not anymore, not for us who live in these dark times. We only have the present, the finger on the trigger, the running of things, an infinite number of things.
Again a masterpiece 🌟
Fantastic writing as always! This Event Bus reminds me of the homegrown "orchestration" we had in one of my previous workplaces: it was just Google Pub/Sub consuming logs and triggering functions in response to them. Setting up was a pain and observability essentially inexistent, but when it did work, it was super smooth and quick to propagate changes across the whole graph.